갤럭시 AI 글로벌 연구소 3화: 베트남(SRV)
삼성전자의 갤럭시 S24를 통해 새로운 차원의 모바일 AI 시대가 펼쳐진 이후, 언어의 장벽이 점차 무너져 가고 있다. 그렇다면 자유로운 의사 소통을 위한 새로운 언어를 AI 모델에 학습시킨다는 것은 과연 어떤 의미이고 무엇을 말하는 것일까? 지난 2화 ‘요르단 연구소(SRJO)편’에서 언어의 방언을 인식하고 학습하는 복잡한 작업에 대해 살펴보았다면 이번에는 베트남 연구소(SRV)를 찾아가 성조를 인식하고 학습하는 작업에 대해 알아본다.

베트남어는 베트남을 포함해 전 세계 약 9천7백여 만 명이 사용하는 언어로, 중국어, 태국어 등 인근 지역 언어와 비슷한 성조 체계를 지니고 있다. 예를 들어 베트남어 단어 ‘Ma’는 성조에 따라 무덤(Ma), 귀신(Mả) 엄마(Má) 등 전혀 다른 의미를 갖는다.
이러한 언어적 특징은 문맥이나 발화자의 의도, 감정을 직접 인지하지 못하는 AI 모델이 언어를 학습하는 게 매우 어려울 수 있음을 시사한다.
삼성전자 베트남 연구소(SRV)는 이를 극복하기 위해 AI 모델을 학습시킬 때 언어의 미세한 차이를 인식할 수 있도록 매우 정교하게 다듬은 데이터를 활용했다. 이때 활용된 데이터는 자동 음성 인식(Automatic Speech Recognition, 이하 ASR), 신경망 기계 번역(Neural Machine Translation, 이하 NMT), 텍스트 음성 변환(Text to Speech, 이하 TTS) 등 AI 모델의 결과물과 정확도에 직접적 영향을 미친다.
고품질 데이터를 활용한 갤럭시 AI는 실시간 번역, 통역, 챗 어시스트, 노트 어시스트 등 실생활에 자주 활용되는 경험을 제공해 사용자의 언어 장벽을 크게 낮출 수 있었다.
6개 성조에 따라 달라지는 단어의 의미
“베트남어는 음성 구조가 복잡하고 표현도 풍부해 개발자들에게 매우 도전적인 과제였습니다.” 베트남 연구소에서 NMT 모델 개발을 리드한 응오 홍 타이는 갤럭시 AI의 16개 언어 중에서, 베트남어의 난이도가 특히 높아 개발자로서 매우 도전적인 과제였다고 말했다.

“제게는 이번 개발 과정이 악명 높은 베트남의 태풍보다 더 무서웠다”며 웃음을 보인 그는 베트남어 AI 언어를 개발하는 과정에서 팀이 직면하고 극복해야 했던 장애물과 어려움에 대해 설명했다.
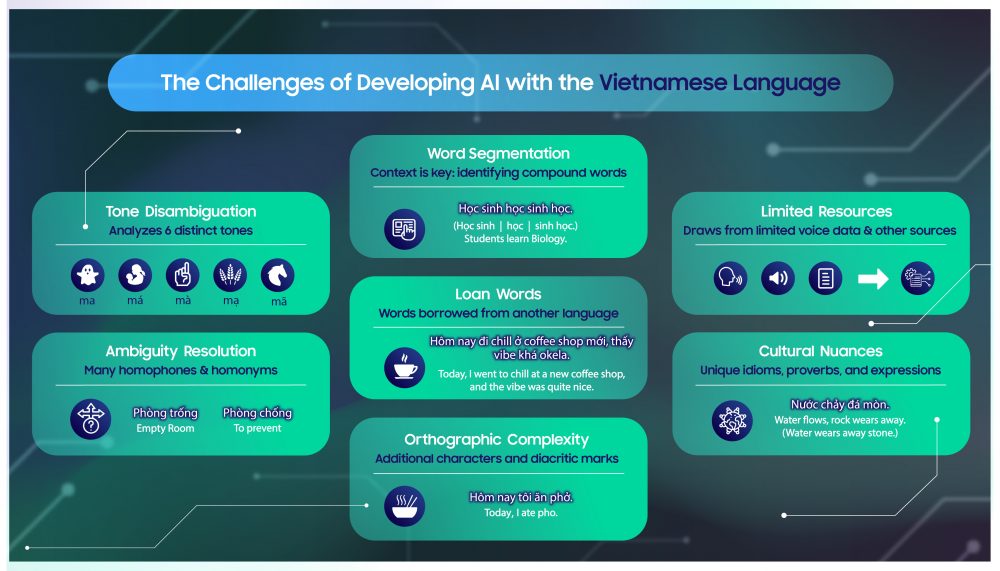
개발 과정이 호락호락하지 않았던 첫 번째 이유는 앞서 언급했던 것처럼 베트남어가 여섯 가지 성조를 가진 음조 언어라는 데 있었다. 발성의 작은 차이가 단어의 의미를 크게 바꿀 수 있기에 더욱 세밀한 접근이 필요했다.
“서로 비슷하게 들리는 단어도, 매우 짧은 세그먼트로 나누면 한 단어당 여러 프레임 세트씩 구성됩니다.” 삼성전자 베트남 연구소에서 ASR 개발을 리드하고 있는 부이 응옥 뚱의 말이다.

그는 “AI 모델은 0.02초 전후의 짧은 프레임을 구분해 연속된 프레임 세트에 해당하는 단어가 무엇인지 인식하기 때문에 초기 AI 학습 과정에 심혈을 기울여야 한다”고 부연 설명했다.
개발자들은 두 번째 어려움으로, 발음은 같지만 의미가 다른 동음이의어와 철자가 같지만 의미가 다른 동형이의어가 흔한 점을 꼽았다.
사람끼리 대화할 때는 유사한 소리나 문자를 분위기나 발화자의 비언어적 요소에 따라 구분해 알아들을 수 있지만, AI 모델은 그렇지 않다. 따라서 AI 모델이 성조와 유사한 단어를 정확히 구분하도록 트레이닝시키는 것이 필수적이다. 응오 홍 타이는 이 과정이 말처럼 간단하지 않았다고 덧붙였다.
“AI 모델을 학습시킬 때 사용되는 데이터의 양뿐 아니라 데이터의 정확성도 매우 중요해요. 그래야만 베트남어에 존재하는 미묘한 차이를 AI 모델이 인지할 수 있기 때문이죠.”

엄격한 데이터 정제 과정
데이터 정제 과정은 크게 세 단계로 구성된다.
먼저, 트레이닝에 사용될 오디오와 텍스트 데이터를 검토하고 이를 수정한다.
다음으로, 데이터 세트의 전반적인 품질을 한 차례 더 확인하기 위해 무작위 검사를 수행하고, 마지막으로, 트레이닝이 시작되기 전 데이터 세트를 최종 정리한다.
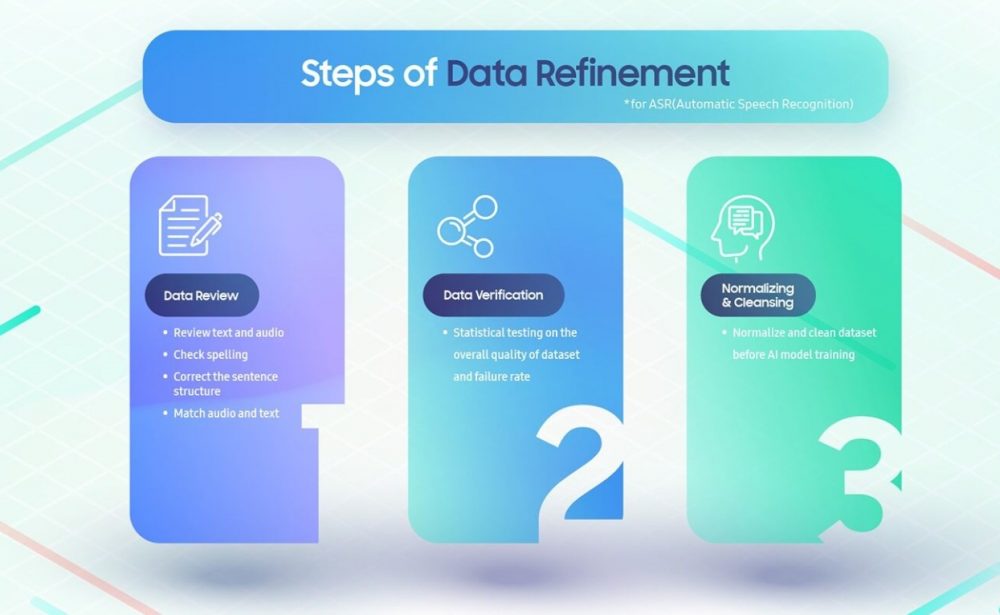
데이터베이스 생성을 총괄하고 TTS 모델 개발을 담당한 응우웬 마인 쥬이는 “데이터 세트의 정확도를 확인하기 위해 정제 활동을 철저히 수행했다”고 밝히며, “녹음 중 스크립트 속의 오타를 발견하거나 소음이 유입되거나, 발음이 부정확해지는 등 예상치 못한 많은 문제가 발생했고, 그런 만큼 정제 과정에 많은 시간을 쏟아 트레이닝 데이터를 개선했다”며 그동안의 어려움에 대해 회고했다.

갤럭시 AI 베트남어 개발에 있어 또 다른 어려움으로 데이터 소스가 제한적이라는 점도 있었다. 응우웬은 “이는 데이터 정제 단계가 매우 중요한 또 다른 이유”라고 덧붙이며, “사용할 수 있는 외부 소스가 제한적이기 때문에 우리가 갖고 있던 데이터의 신뢰도를 높여야 했다. 데이터에 오류가 발견되면 ‘실패’라는 비장한 마음가짐으로 임했다”고 말했다. 응우웬의 목소리에는 우리가 해냈다는 자부심과 자신감이 가득 차 있었다.

베트남어 AI 모델은 언어의 지역적 차이도 극복해야 했다. 이를 위해 개발팀은 베트남 북부는 물론, 중부와 남부 악센트에 대한 대량의 데이터를 수집했고, 이 방대한 양의 데이터를 정제하고 검증하기 위해 전 팀원들이 치열하게 노력했다.
끝이 아니라 시작
삼성전자 베트남 연구소 담당자들은 각고의 노력 끝에 개발을 완료했고, 베트남어는 이제 갤럭시 AI와 함께 출시된 최초의 언어 중 하나가 되었다. 이러한 성취에도 불구하고, 팀은 계속해서 베트남어 갤럭시 AI 경험을 낫게 하기 위해 끊임없이 노력하고 있다.
SRV의 AI 언어 개발 프로젝트 팀장 쩐 뚜언 밍은 “갤럭시 AI에서 단어와 구절의 관련성에 대한 사용자의 피드백을 받으며 AI 모델은 지속적으로 진화하고 있다”, “우리는 이제 첫 걸음을 내디뎠고 앞으로도 더 나은 사용 경험을 소비자들에게 제공하도록 노력할 것”이라고 각오를 다졌다.

다음 편에서는 중국연구소를 방문해, 데이터 학습 이후 AI 모델을 빌드하는 과정을 자세하게 조명할 예정이다.
: